
Designing my OS
When I design and code my operating system, I usually document what I do in a couple markdown files. I thought maybe some people would find it usefull to see them so I am posting one here. This one is about the networking architecture of my OS. Note that this is really the product of my imagination so it might not be (or should I say it definitely isn't) the best way of doing things. It's just the way I imagined it and it actually works.
Of course, I can't pretend this is only the product of my imagination. I did get a lot of inspiration from many sources online. But I tend to stay away (as much as I can) from the linux source code. Since I think Linux is such a great implementation, it would be too easy to assimilate a lot of its concepts while looking at it. Because once you look at it, you realize that what you're looking at is probably the best way to do things. Take sockets for example. Once you are used to using sockets with open/send/recv/close, how else would you do it? So I ended up doing that because it's what I know. But I have no idea how linux works behind the socket implementation, so I tried to design it the way I think it works. I'm not looking at conceiving the best thing, I'm looking at picking my brain and create something that works the way I imagined it. Maybe like art instead of science.
There are flaws and still open questions but it does work. I don't have any code to post here because I am thinking on either posting the whole code on my website or on github. I have to sort that out.
Network card drivers
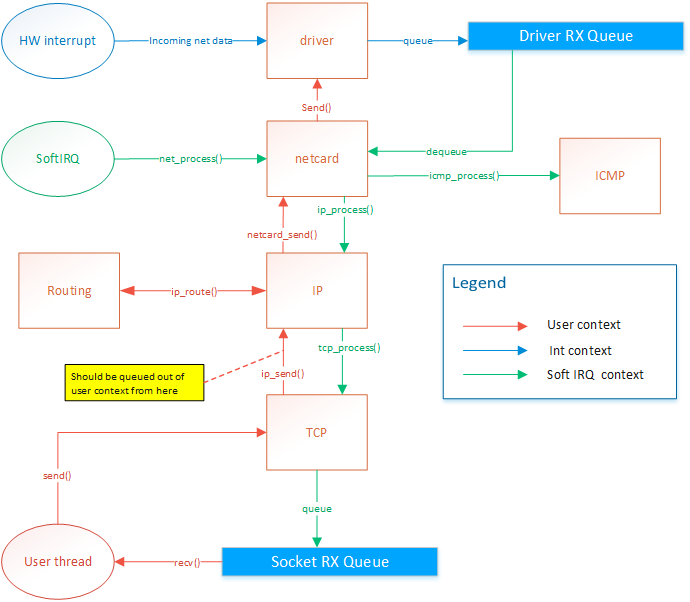
The netcard abstration layer is contained in netcard.c.
When the OS boots, net_init() is called. This function iterates through the PCI bus's devices to find all devices that match one of the OS's netcard drivers. For each netcard found, a struct NetworkCard is instanciated. The structure contains several function pointers that are initialized with the matching driver's functions. For example, NetworkCard::receive would be set to &rtl8139_receive if the netcard was a rtl8139. Each of these NetworkCard instances will be refered to as the "netcard implementation"
Only the rtl8139 driver is implemented right now. You can view the source code I have posted a while ago in Realtek 8139 network card driver
When a netcard IRQ occurs, a softIRQ is scheduled. (I know, softIRQ is a linux concept. But I actually thought about it before knowing it existed in linux. I didn't have a name for it so I found that Linux had a great name so I stole it. But it doesn't really work like linux's softIRQ. Linux has a way better way of doing it than my OS). When the softIRQ handler is invoked, it calls net_process(). net_process() iterates through all netcard that was discovered during boot. It then checks if data is available and forwards the the data up to the TCP/IP stack if the data is an IP packet, or to the ICMP stack if the packet is of the ICMP type.
TCP/IP stack
Receiving data
The ICMP handler responds immediately to ping requests. Therefore the ICMP response is sent from the softIRQ thread. This allows consistent RTT. The IP handler forwards the message to the TCP or UDP handlers. The UDP handler is not implemented yet. The TCP handler forwards segments to active sockets by finding the socket listening to the port and ip of the message. This is done by by finding the socket instance within a hash list. The message is added in the socket's queue. The user thread is then responsible for dequeuing those messages.
Sending data
The netcard abstraction's net_send() function locks the netcard implementation's send spinlock. This way, only one thread can send to one given netcard at the same time.
net_send() takes an interface index as destination parameter. ip_send takes an ip address as destination parameter. ip_send invokes ip_routing_route() to determine on what netcard to send the message based the destination address.
net_send() will send 1 frame of maximum MTU size. It returns 0 if sending failed or size of frame if sending suceeded. Frames are guaranteed to be sent in full or not at all but never partly.
ip_send() will send a packet of maximum 65536 bytes. It will do ip fragmentation in order to send frames of appropriate size.
tcp_send() will send 1 segment of maximum 64k. This means that the underlying ip_send() can end up calling net_send several times.
There is actually a design flaw with tcp_send right now. Sending data on a socket will end up in netcard_send being called from the user thread. The call is thus blocking.
Also, If net_send() returns 0, because of HW buffer overflow, then ip_send will return the number of bytes sent. But tcp_send should not attempt to send the rest of the data because the IP protocol expects the rest of the packet.
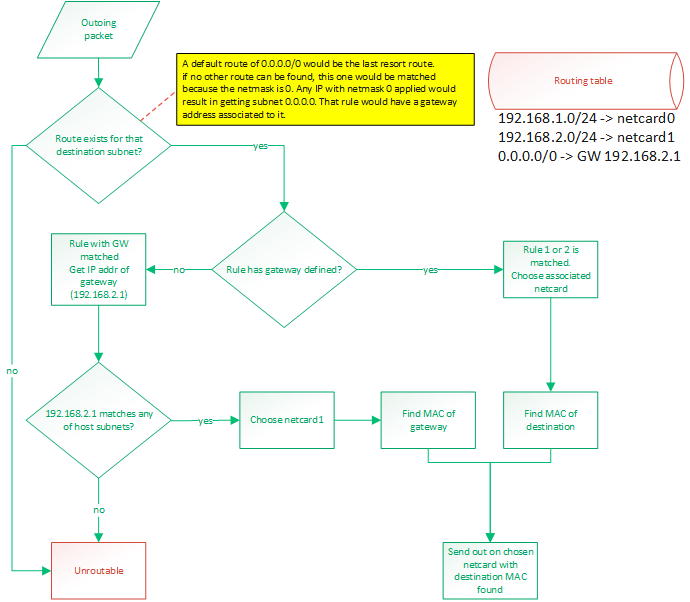
IP routing
IP routing is a whole subject itself. There are many algorithms and many ways to do this. It's actually the center of a very big industry. Basically, when a packet needs to be sent out, we know destination IP to which we want to send. The OS needs to know out of with netcard (if there are more than one) to send the packet and it also needs to know the source IP address to put in the packet. Normally, there would be one IP per netcard. Linux allows you to setup multiple IP for one physical netcard, so this would be done by creating virtual netcards. So the rule would still hold: 1 IP per netcard. My OS does not support virtual netcards, so only one IP per physical netcards.
This is all done with a routing table. By default, the routing table will consist of an entry for each IP configured IP for the host. Those route would be something like "anything within my own LAN must be forwarded out on my netcard". So if netcard0 has IP 192.168.1.88/24 and netcard1 has IP 192.168.2.25/24 then the routes would be:
- 192.168.1.0/24 -> netcard with IP 192.168.1.88 (netcard0)
- 192.168.2.0/24 -> netcard with IP 192.168.2.25 (netcard1)
A route can either say:
- if destination IP matches my subnet, then route out of interface X
- if destination IP matches my subnet, then route out to GW with IP address X
To match a rule, the rule's netmask is applied to the destination IP and the rule's IP. These masked IPs are subnets. If both subnets match, then the rule matches. A rule of 0.0.0.0/0 would be a default route and would guarantee to always match. It would be the last resort route.
Usually, routing out of an interface is done when we expect a device connected on that interface (through a switch probably) to be able to recognize that destination IP. When routing to a GW IP, it is because we expect a specific device to know where to find that destination IP. This would be a router. A default route would be configured like that. If an outgoing packet's destination IP address matches the default route, it means it couldn't match any of the other routes. So we want to send that packet to a gateway. We expect the gateway to be able to route the packet because our own routing table can't.
So the destination subnet is verified in order to find a route for that subnet. The subnet is the IP address logically AND'ed with the netmask.
Then a route for the default gateway must be added. This will tell: "Anything not matched in the LAN IPs must be sent to this IP". So something like: 0.0.0.0/24 -> 192.168.2.1. So if something needs to be sent to 192.168.5.6 then that route would be matched. The OS would then compare the subnet (using the netmask) of that gateway with the IPs configured on the host. It would find that this IP (of the gateway) is on the same LAN than 192.168.2.25 so netcard1 will be chosen as the outgoing netcard and the destination MAC address of the gateway will be used. So it is clear that using a gateway that reside on a subnet that doesn't match any of the host's IPs would be an invalid configuration.
Frame forwarding
At the layer 2, devices don't know about IP addresses. They only know about MAC addresses. Only devices connected together on the same layer 2 network (physically connected with switches) can talk to each other. When a packet is ready to be sent out, its MAC address might not be known yet. The OS will discover it by sending an ARP request: "who has IP 192.168.2.1?". Then, that device will answer "Me, and my MAC is xx:xx:xx:xx:xx:xx". So that destination MAC address will be used. When sending a packet to an external network, that is behind a router, such as the example of 192.168.5.6 earlier, the destination MAC of the gateway will be used. So if we send a packet to a device (by selecting its MAC as the destination) but the destination IP does not match that device's IP, it means we are expecting that device to be able to do layer 3 routing. Such a device would generally be a router. But it could also be any workstation on the LAN. Those workstations could be able to route. Linux does it.
Blocking operations
All socket operations such as connect, accept, send, receive and close are non-blocking. This implies that the lower-level layer operations are non-blocking also. There are some exceptions to this, but only because there are design flaws that need to be addressed.
Locking
At any time, only two threads can access the tcp/ip stack: The softIRQ thread, for processing incomming frames, and the owner of the socket. If multiple threads want to share socket usage, they will have to implement their own locking mechanism. The tcp/ip stack will only guarantee thread safety between the two threads mentioned above. Sockets should be used by one thread only in a user application. Two different sockets can be used by two different threads at the same time though.
net_send() locking
net_send() is used by the softIRQ context and user threads. Since the softIRQ context has high priority, it means that if a thead is preempted while it was holding the netcard's send spinlock, and then the softIRQ attempts to request the lock, a deadlock might occur. On uni-CPU systems, a deadlock would occur because the softIRQ will never give CPU time to other threads until it has completed its work. This could also happen on systems where the number of netcard is greater than or equal to the number of CPUs.
To solve this problem, the spinlock will disable interrupts.
- Spinlock will prevent another CPU from accessing the send function
- The thread would not be preempted on the local CPU so there is no chances that a softIRQ would deadlock (since softIRQ are prioritized over that thread, it could continue to run and never give time to the thread to release the lock).
- On a single-CPU system, the interrupt cleared and spinlock would be redundant but would not cause a problem
Socket locking
No locking is currently done at the socket level. The following is a list of problems that would arise, and the associated solution
- Make sure a thread does not delete its socket while softIRQ is using it.
- A thread might want to get the seqnumber while the softirq is modifying it.
- A thread might read in the receive queue while softIRQ is writing in it
??????
Make sure that only one consumer at a time can append/remove from the socket list.
Solution The hash list is thread safe so it should already be handled correctly. But more tests need to be done because there is a little more to it than just accessing the hash list.
Socket backlog list might get accessed by softIRQ and owning thread
Solution
??????
Accepting incomming connections
A socket is created using create_socket(). Then the socket is placed in listening mode with listen(). listen() will set the source ip/port of the socket as per parameters of the function and destination ip/port to 0. A backlog buffer is created with size=(sizeof(socket*)*backlogCount).
When a segment is processed by tcp_process (in softirq context), a socket will try to be matched. If no socket is found then tcp_process() will try to find a listening socket that uses the same source ip/port (matching the received segment's destination fields) and with destination ip/port set to 0. if a socket is found, then we know that this segment is for an incomming connection.
The listening socket will only process SYN segments and will ignore any other segments. When processing a SYN segment, it will create a new socket with the same source ip/port and with destination ip/port matching the source of the incomming segment. The state will be set to CONNECTING. The new pending socket will be saved in the listening socket's backlog. The new socket will stay in the backlog until it gets picked up by accept(). accept() will then move the socket to the main list. The socket created in the backlog is only temporary. accept() will create a new socket instance based on that socket so that the new instance will reside in the accepting process's heap.
When the accept function is called, it will go through the backlog of the listening socket and will finish creating the socket. It will clone the socket and create the receive buffer and send the syn/ack. The socket will stay in "CONNECTING" state until it receives the ack of the syn/ack accept will move the socket from the backlog to the main list.
Other articles about my OS
Process Context ID and the TLB
Thread management in my hobby OS
Enabling Multi-Processors in my hobby OS
Block caching and writeback
Memory Paging
Stack frame and the red zone (x86_64)
AVX/SSE and context switching
Realtek 8139 network card driver