The code for this project is, again, available on github: https://github.com/pdumais/OpenflowController. I am not using any OF libraries, this is 100% home-made.
Intro
The objective with this project is to be able to create virtual networks that span across several switches. For example, I have 5 VMs that run in a 10.0.0.0/24 subnet but those VMs are on different hypervisors. I want my controller to create an overlay network for those, and only those, VMs. It is possible to have many overlays with the same addressing space because the switches will only forward traffic between hosts part of the same overlay
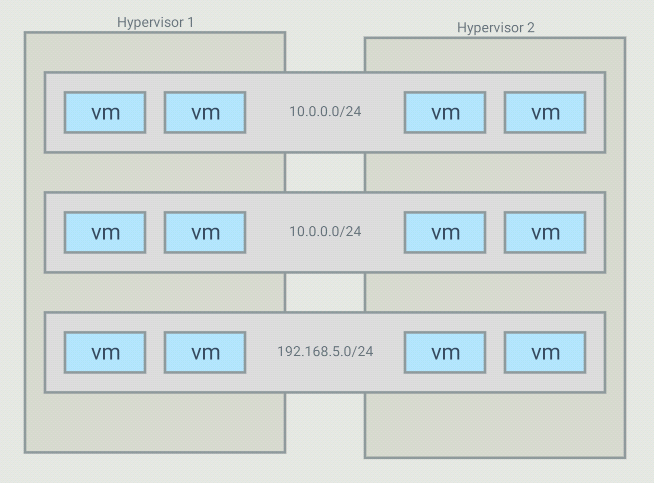
For such a topology, OVS bridges end up looking like this:
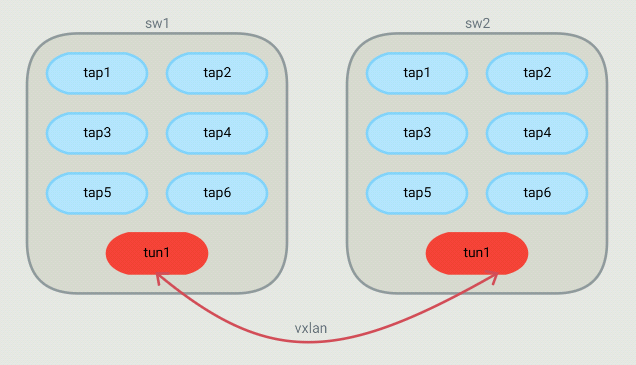
The controller
On the controller, I configure 4 types of objects: Bridges, Networks, Routers and Hosts. A host is a VM or a container (or anything using a TAP interface in the OVS bridge). Each host is part of a bridge. In general, you'd setup one bridge per hypervisor. So because I define where bridges are (on which hypervisor they run), the controller knows that 2 hosts run on different hypervisors and they should communicate through a tunnel. Each host is part of a network. Those are virtual network that I define in the controller. The controller will allow communication between hosts that are on the same virtual network. A virtual network can span across many bridges. From the controller's point of view, all the configuration is static. For each host, I define the bridge it is on, the port number it is using, it's IP address and mac address. The mac,port,bridge could be given to the controller by some kind of agent that would run on the HV but in my case, I have just hardcoded those values. The IP address of the VM can be set to anything.
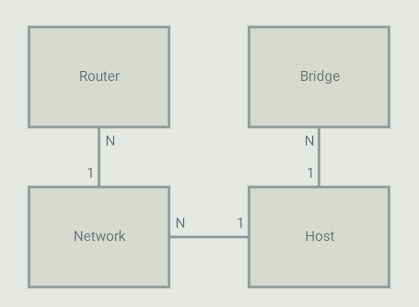
Flows
DHCP
Since I pre-configure the controller with the list of hosts that will attach to it with their MAC, IP and networkID, gateway IP etc., the controller has all the information it needs to act as a DHCP server. So the controller adds a flow, 1 for every host that is local to the hypervisor, to match the source MAC/port and UDP port 67 with an action to send the packet to the controller. The controller then crafts a DHCP reply packet and sends it back on the ingress port.
ARP
Again, since the controller has all information about the hosts, it is also capable of responding to ARP queries. Flows are installed to intercept any ARP query and the controller will craft a response. If a host makes an ARP query, that query will never be flooded (not even on the vxlan tunnel) and will never be seen by anyone else than the controller. Technically, no hosts should ever receive ARP requests.
Table 0
Table 0 contains the flows to match ARP and DHCP requests. If a packet does not match any flow in Table 0, a table-miss flow will send the packet to Table 1.
Table 1
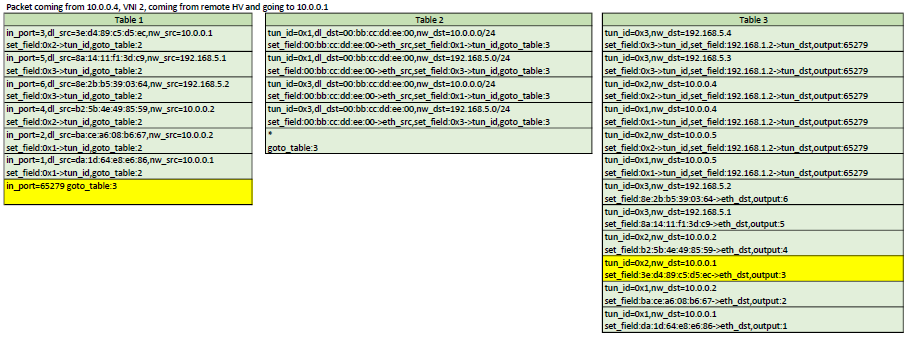
Table 1 is about matching the source of a packet. For each host on the current bridge, a flow that matches the in_port,src_mac,src_ip will be installed. The actions are to set the virtual network ID in the tunnel_id metadata (will be used in Table 3) and then goto Table 2 Another flow that matches the tunnel in_port is installed with an action to goto Table 3. That tunnel flow doesn't set the tunnel_id metadata because it was already set when the packet came through the tunnel. The tunnel_id of a packet coming in from a VXLAN tunnel is the VNI.
Table 2
Table 2 has flows that match dst_mac set to gateway addresses as defined in Router objects. These flows are used for routing between virtual networks. If the dst_mac is not for a virtual router, then a table-miss flow sends the packet to table 3.
Table 3
Table 3 is about forwarding to the correct host. When a packet enters Table 3, it is guaranteed to have a tunnel_id (set as the virtual network ID). Table 3 contains 1 flow for each host known across all virtual networks. All flows match the tunnel_id,dst_mac,dst_ip. The action depends on if the host is local or resides on another hypervisor. If it is local, then the action is simply to forward to the port of that host. If it is remote, then 2 actions are executed: Set-Field for remote tunnel endpoint IP and output to the tunnel port. Note that since the tunnel_id is set (in table 1), the VXLAN packet created by OVS will have that ID as the VNI. So when entering the other HV, a flow will match that to the virtual network ID of the host.
So since the controller knows about all VMs and virtual networks, it is able to install those flows that will make traffic between hosts part of the same virtual network possible, even across hypervisors, thanks to VXLAN tunnels.
Example flows
Here is an example of the flows created on Hypervisor 1 from the above example setup
First, we see that in table 0, we intercept all ARP queries from all local hosts and send them to the controller. The controller will respond if the target is a local or a remote host
cookie=0x200000000000000, duration=20.254s, table=0, n_packets=0, n_bytes=0, priority=101,arp,in_port=3,dl_src=3e:d4:89:c5:d5:ec,arp_op=1 actions=CONTROLLER:65535
cookie=0x200000000000000, duration=20.253s, table=0, n_packets=2, n_bytes=84, priority=101,arp,in_port=5,dl_src=8a:14:11:f1:3d:c9,arp_op=1 actions=CONTROLLER:65535
cookie=0x200000000000000, duration=20.253s, table=0, n_packets=0, n_bytes=0, priority=101,arp,in_port=6,dl_src=8e:2b:b5:39:03:64,arp_op=1 actions=CONTROLLER:65535
cookie=0x200000000000000, duration=20.252s, table=0, n_packets=0, n_bytes=0, priority=101,arp,in_port=4,dl_src=b2:5b:4e:49:85:59,arp_op=1 actions=CONTROLLER:65535
cookie=0x200000000000000, duration=20.252s, table=0, n_packets=0, n_bytes=0, priority=101,arp,in_port=2,dl_src=ba:ce:a6:08:b6:67,arp_op=1 actions=CONTROLLER:65535
cookie=0x200000000000000, duration=20.251s, table=0, n_packets=0, n_bytes=0, priority=101,arp,in_port=1,dl_src=da:1d:64:e8:e6:86,arp_op=1 actions=CONTROLLER:65535
Then, in table 0 still, we intercept DHCP requests. The last flow is the table-miss flow that will make us jump to table 1
cookie=0x100000000000000, duration=20.254s, table=0, n_packets=0, n_bytes=0, priority=100,udp,in_port=3,dl_src=3e:d4:89:c5:d5:ec,tp_dst=67 actions=CONTROLLER:65535
cookie=0x100000000000000, duration=20.253s, table=0, n_packets=1, n_bytes=342, priority=100,udp,in_port=5,dl_src=8a:14:11:f1:3d:c9,tp_dst=67 actions=CONTROLLER:65535
cookie=0x100000000000000, duration=20.253s, table=0, n_packets=0, n_bytes=0, priority=100,udp,in_port=6,dl_src=8e:2b:b5:39:03:64,tp_dst=67 actions=CONTROLLER:65535
cookie=0x100000000000000, duration=20.252s, table=0, n_packets=0, n_bytes=0, priority=100,udp,in_port=4,dl_src=b2:5b:4e:49:85:59,tp_dst=67 actions=CONTROLLER:65535
cookie=0x100000000000000, duration=20.252s, table=0, n_packets=0, n_bytes=0, priority=100,udp,in_port=2,dl_src=ba:ce:a6:08:b6:67,tp_dst=67 actions=CONTROLLER:65535
cookie=0x100000000000000, duration=20.251s, table=0, n_packets=0, n_bytes=0, priority=100,udp,in_port=1,dl_src=da:1d:64:e8:e6:86,tp_dst=67 actions=CONTROLLER:65535
cookie=0x8a22420000000000, duration=20.255s, table=0, n_packets=0, n_bytes=0, priority=0 actions=goto_table:1
Now in table 1, we match the source of all known local hosts and set the tun_id field (VNI), which is a way for us to tag the packet with its network ID. The last flow matches the in_port 65279, which is the tunnel port. It will make us jump to table 2. The tun_id is already set for all packets comming in from the tunnel
cookie=0x200000000000000, duration=20.254s, table=1, n_packets=0, n_bytes=0, priority=300,ip,in_port=3,dl_src=3e:d4:89:c5:d5:ec,nw_src=10.0.0.1 actions=set_field:0x2->tun_id,goto_table:2
cookie=0x200000000000000, duration=20.253s, table=1, n_packets=0, n_bytes=0, priority=300,ip,in_port=5,dl_src=8a:14:11:f1:3d:c9,nw_src=192.168.5.1 actions=set_field:0x3->tun_id,goto_table:2
cookie=0x200000000000000, duration=20.253s, table=1, n_packets=0, n_bytes=0, priority=300,ip,in_port=6,dl_src=8e:2b:b5:39:03:64,nw_src=192.168.5.2 actions=set_field:0x3->tun_id,goto_table:2
cookie=0x200000000000000, duration=20.252s, table=1, n_packets=0, n_bytes=0, priority=300,ip,in_port=4,dl_src=b2:5b:4e:49:85:59,nw_src=10.0.0.2 actions=set_field:0x2->tun_id,goto_table:2
cookie=0x200000000000000, duration=20.252s, table=1, n_packets=0, n_bytes=0, priority=300,ip,in_port=2,dl_src=ba:ce:a6:08:b6:67,nw_src=10.0.0.2 actions=set_field:0x1->tun_id,goto_table:2
cookie=0x200000000000000, duration=20.251s, table=1, n_packets=0, n_bytes=0, priority=300,ip,in_port=1,dl_src=da:1d:64:e8:e6:86,nw_src=10.0.0.1 actions=set_field:0x1->tun_id,goto_table:2
cookie=0x0, duration=20.255s, table=1, n_packets=0, n_bytes=0, priority=200,in_port=65279 actions=goto_table:3
In table 3, we match the tun_id and the destination and forward out to the appropriate port if the destination host is local
cookie=0x0, duration=20.254s, table=3, n_packets=0, n_bytes=0, priority=400,ip,dl_dst=52:21:f7:11:a6:10,nw_dst=192.168.5.4 actions=set_field:0x3->tun_id,set_field:192.168.1.2->tun_dst,output:65279
cookie=0x0, duration=20.254s, table=3, n_packets=0, n_bytes=0, priority=400,ip,dl_dst=5e:9f:86:77:6e:87,nw_dst=192.168.5.3 actions=set_field:0x3->tun_id,set_field:192.168.1.2->tun_dst,output:65279
cookie=0x0, duration=20.254s, table=3, n_packets=0, n_bytes=0, priority=400,ip,dl_dst=74:4b:c6:95:18:73,nw_dst=10.0.0.4 actions=set_field:0x2->tun_id,set_field:192.168.1.2->tun_dst,output:65279
cookie=0x0, duration=20.254s, table=3, n_packets=0, n_bytes=0, priority=400,ip,dl_dst=7e:cc:09:63:aa:6f,nw_dst=10.0.0.4 actions=set_field:0x1->tun_id,set_field:192.168.1.2->tun_dst,output:65279
cookie=0x0, duration=20.253s, table=3, n_packets=0, n_bytes=0, priority=400,ip,dl_dst=86:95:72:30:f5:ac,nw_dst=10.0.0.5 actions=set_field:0x2->tun_id,set_field:192.168.1.2->tun_dst,output:65279
cookie=0x0, duration=20.251s, table=3, n_packets=0, n_bytes=0, priority=400,ip,dl_dst=ea:3d:e4:bc:b6:9f,nw_dst=10.0.0.5 actions=set_field:0x1->tun_id,set_field:192.168.1.2->tun_dst,output:65279
These last flows, in Table 3 again, match the destination of all remote hosts and forwards the packet out of the tunnel port after having set the tunnel destination address (address of the HV running that host)
cookie=0x200000000000000, duration=20.254s, table=3, n_packets=0, n_bytes=0, priority=300,ip,tun_id=0x2,dl_dst=3e:d4:89:c5:d5:ec,nw_dst=10.0.0.1 actions=output:3
cookie=0x200000000000000, duration=20.253s, table=3, n_packets=0, n_bytes=0, priority=300,ip,tun_id=0x3,dl_dst=8a:14:11:f1:3d:c9,nw_dst=192.168.5.1 actions=output:5
cookie=0x200000000000000, duration=20.253s, table=3, n_packets=0, n_bytes=0, priority=300,ip,tun_id=0x3,dl_dst=8e:2b:b5:39:03:64,nw_dst=192.168.5.2 actions=output:6
cookie=0x200000000000000, duration=20.252s, table=3, n_packets=0, n_bytes=0, priority=300,ip,tun_id=0x2,dl_dst=b2:5b:4e:49:85:59,nw_dst=10.0.0.2 actions=output:4
cookie=0x200000000000000, duration=20.252s, table=3, n_packets=0, n_bytes=0, priority=300,ip,tun_id=0x1,dl_dst=ba:ce:a6:08:b6:67,nw_dst=10.0.0.2 actions=output:2
cookie=0x200000000000000, duration=20.251s, table=3, n_packets=0, n_bytes=0, priority=300,ip,tun_id=0x1,dl_dst=da:1d:64:e8:e6:86,nw_dst=10.0.0.1 actions=output:1
VXLAN tunnels
I had a hard understanding how to create the tunnels at first. I know that with OVS, we can create VXLAN tunnel ports and we just need to forward traffic on those ports. But this requires configuring (N-1) tunnel ports on each hypervisors if we have a total of N hypervisors. So instead I found that there is an openflow extension (so not part of the official spec) that allows to set the destination of the tunnel dynamically with a flow. This is done with a "set-field" action, with a OXM class of 0x001 and field ID 32 (this is a Nicira extension). Then you only need to create 1 tunnel port per hypervisor like this:
ovs-vsctl add-port sw1 vtun1 -- set interface vtun1 type=vxlan options:remote_ip=flow options:key=flow
Using "flow" as the remote_ip allows us to set the destination IP using flows. And setting key=flow allows us to set the VNI with flows.
Routing
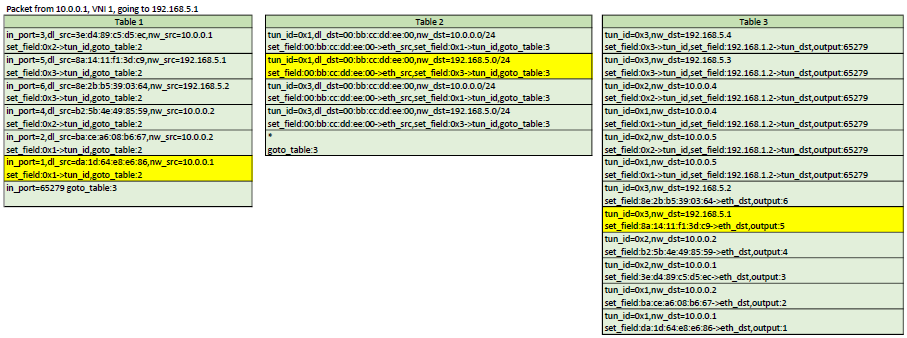
Routing is a very simple process. When a host sends a packet to another host, on another network, it simply uses the mac address of the gateway as the destination mac. So from the switch's point of view, it's just a matter of detecting that "special" mac address and allowing to forward on a port that is on a different virtual network.
In my controller, this done by configuring a Router object in the controller and adding networks it. The router will allow communication between networks associated to it. When a host needs to send traffic to another network, it needs to go through a gateway. in the configuration shown above, we can see that an IP has been assigned as the gateway ip in each network. The controller will respond to arp queries for those gw IP with the mac adress of the virtual router that those networks are associated to. So hosts will be sending their inter-network traffic using the virtual router's mac as the destination mac.
So the controller can install flows to match traffic with that mac and the dst_ip (with a mask) to change the network id on that packet. the packet can then be sent to table 3 for proper port forwarding.
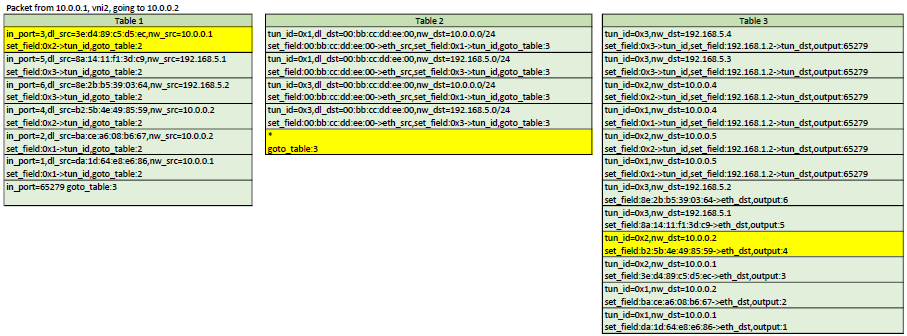
Example flows
Here is a representation of table 1,2,3. In each scenario, the yellow flows are the ones that would be matched

Configuration
Like I've mentionned above, right now, the configuration is very static. We have to pre-configure the controller and tell it exactly where (on which HV) each VMs runs, the port number in the OVS they are attached to and their MAC address. Although the controller could deduct some of that information, I prefer to tell it exactly what I am expecting so I can exercise better control over my network.
u8 mac1[] = {0xda,0x1d,0x64,0xe8,0xe6,0x86};
u8 mac2[] = {0xba,0xce,0xa6,0x08,0xb6,0x67};
u8 mac3[] = {0x3e,0xd4,0x89,0xc5,0xd5,0xec};
u8 mac4[] = {0xb2,0x5b,0x4e,0x49,0x85,0x59};
u8 mac5[] = {0x8a,0x14,0x11,0xf1,0x3d,0xc9};
u8 mac6[] = {0x8e,0x2b,0xb5,0x39,0x03,0x64};
u8 mac7[] = {0x7e,0xcc,0x09,0x63,0xaa,0x6f};
u8 mac8[] = {0xea,0x3d,0xe4,0xbc,0xb6,0x9f};
u8 mac9[] = {0x74,0x4b,0xc6,0x95,0x18,0x73};
u8 mac10[] = {0x86,0x95,0x72,0x30,0xf5,0xac};
u8 mac11[] = {0x5e,0x9f,0x86,0x77,0x6e,0x87};
u8 mac12[] = {0x52,0x21,0xf7,0x11,0xa6,0x10};
// We define the hypervisor with their datapath ID and management IP
this->addBridge(0x32d1f6ddc94f,"192.168.1.216");
this->addBridge(0x4e7879903e4c,"192.168.1.2");
// Define overlay networks: id, net, mask, GW ip, DNS server
this->addNetwork(1,"10.0.0.0","255.255.255.0","10.0.0.254","10.0.0.250");
this->addNetwork(2,"10.0.0.0","255.255.255.0","10.0.0.253","10.0.0.249");
this->addNetwork(3,"192.168.5.0","255.255.255.0","192.168.5.253","192.168.5.249");
// We will create 1 router to be able to route between network 1 and 3
// We can route between 1 and 2 because they have the same network address
this->addRouter(0x00bbccddee00);
this->addNetworkToRouter(this->routers[0x00bbccddee00],this->networks[1]);
this->addNetworkToRouter(this->routers[0x00bbccddee00],this->networks[2]);
// Define the hosts: mac, network ID, port, IP, hypervisor ID
this->addHost(extractMacAddress((u8*)mac1),1,1,"10.0.0.1",0x32d1f6ddc94f);
this->addHost(extractMacAddress((u8*)mac2),1,2,"10.0.0.2",0x32d1f6ddc94f);
this->addHost(extractMacAddress((u8*)mac3),2,3,"10.0.0.1",0x32d1f6ddc94f);
this->addHost(extractMacAddress((u8*)mac4),2,4,"10.0.0.2",0x32d1f6ddc94f);
this->addHost(extractMacAddress((u8*)mac5),3,5,"192.168.5.1",0x32d1f6ddc94f);
this->addHost(extractMacAddress((u8*)mac6),3,6,"192.168.5.2",0x32d1f6ddc94f);
this->addHost(extractMacAddress((u8*)mac7),1,1,"10.0.0.4",0x4e7879903e4c);
this->addHost(extractMacAddress((u8*)mac8),1,2,"10.0.0.5",0x4e7879903e4c);
this->addHost(extractMacAddress((u8*)mac9),2,4,"10.0.0.4",0x4e7879903e4c);
this->addHost(extractMacAddress((u8*)mac10),2,5,"10.0.0.5",0x4e7879903e4c);
this->addHost(extractMacAddress((u8*)mac11),3,6,"192.168.5.3",0x4e7879903e4c);
this->addHost(extractMacAddress((u8*)mac12),3,7,"192.168.5.4",0x4e7879903e4c);
So right now, if I create a VM, I need to tell the controller about that new VM and provide the following information:
- MAC address
- Network ID (that will be used as the VNI)
- Hypervisor where the VM runs
- IP Address I want assigned for the VM
- Port number on the OVS bridge
Note that the chosen IP address can be configured manually on the VM, but if choosing DHCP, the controller will intercept the request and assign that IP. So I would need a tool to do this for me instead of doing that step manually after creating a VM. So what could be done next is to create an orchestrator that allows me to spawn VMs on any of the HV (transparently maybe?). At the time of creation, I would need to specify in which network I want my VM to be part of. Then the orchestrator would choose a HV, choose a and IP from the network that was selected and spawn the VM. After spawning the VM, the orchestrator would know the MAC address and the OVS port number that the VM was started with. At that point, the orchestrator has all the information needed to tell the controller how to establish proper networking for that new VM.
What next?
I guess that a cool feature I could do next would be to have a way for those virtual networks to access an external network such as the internet. This would involve NAT and a way route to the underlay. I'll have to think about that one.